해당 챕터는 JPA에 대한 내용이 주를 이루기 때문에 간략하게 정리하였다.
5장은 Specification에 대해 다루는데, QueryDSL이 더 좋은 대안이라고 생각해서 가볍게 훑고 넘어갔다.
1. JPA를 이용한 리포지터리 구현
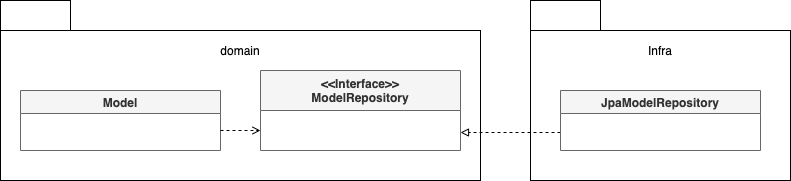
2장에서 언급한 것처럼 리포지터리 인터페이스는 도메인 영역에 속하고, 구현 클래스는 인프라스트럭처 영역에 속한다.
TMI 삭제기능
삭제 요구사항이 있더라도 데이터를 실제로 삭제하는 경우는 많지 않다. 관리자 기능에서 삭제 데이터를 조회하는 경우도 있고 원복을 위해 일정 기간 동안 보관하는 경우도 있기 때문이다. 따라서 데이터를 바로 삭제하기보다는, 삭제 플래그를 사용하는 방식으로 구현하자.
2. 매핑 구현
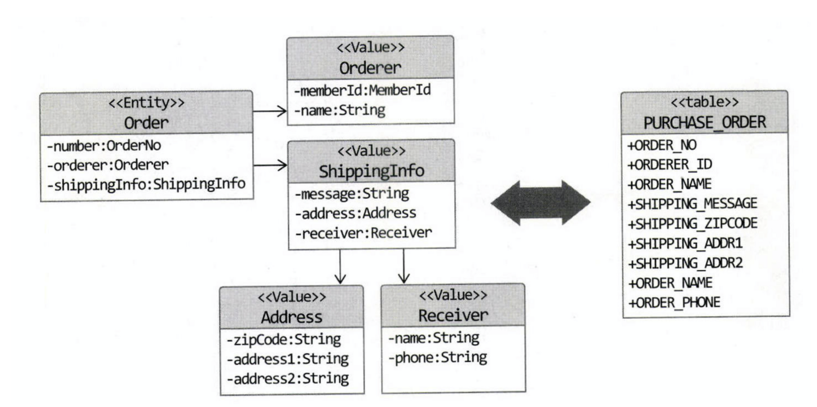
주문 애그리거트는 위와 같이 여러 개의 객체로 구성되지만 테이블은 하나이다. 구현 방법은 아래처럼 @Embeddable과 @Embedded 애노테이션을 사용하면 된다.
@Entity
pulic class Order {
@Embedded
private Orderer orderer;
@Embedded
private ShippingInfo shippingInfo;
...
}
@Embeddable
public class ShippingInfo {
@Embedded
private Address address;
@Embedded
private Receiver receiver;
protected ShippingInfo() {} // JPA에서는 private이 아닌 기본 생성자가 있어야 한다.
public ShippingInfo(Address address, Receiver receiver) {
this.address = address;
this.receiver = receiver;
}
...
}
3. 별도 테이블에 저장하는 밸류 매핑
보통 애그리거트에서 루트 엔티티를 뺀 나머지 구성요소는 대부분 밸류이다. 루트 엔티티 외에 다른 엔티티가 있다면 진짜 엔티티인지 의심하라. 그저 별도 테이블에 저장되어 있는 밸류일 수도 있다. 또는 다른 애그리거트일 수도 있으니 유념하자.
4. 도메인 구현과 DIP
@Entity, @Table은 구현 기술에 속한다. 하지만 해당 애노테이션을 가지는 엔티티는 도메인에 속한다. 즉, 도메인이 인프라에 의존하기 때문에 DIP 위반이다.
DIP를 적용하는 주된 이유는 저수준 구현이 변경되더라도 고수준이 영향을 받지 않도록 하기 위함이다. 하지만 필자는 다음의 이유로 타협해도 된다고 판단하였다.
1. 리포지터리와 도메인 모델의 구현 기술은 거의 바뀌지 않는다. 변경이 거의 없는 상황에서 변경을 대비하는 것은 과하다고 생각한다.
2. JPA 전용 애노테이션을 사용했지만 도메인 모델을 단위 테스트 하는 데 문제없다. 리포지터리 역시 마찬가지다.
'개발 도서 및 강의 > 도메인 주도 개발 시작하기' 카테고리의 다른 글
| 7장 도메인 서비스 (0) | 2023.03.24 |
|---|---|
| 6장 응용 서비스와 표현 영역 (0) | 2023.03.24 |
| 3장 애그리거트 (1) | 2023.03.17 |
| 2장 아키텍처 개요 (0) | 2023.03.17 |
| 1장 도메인 모델 시작하기 (0) | 2023.03.17 |








