1. 애그리거트 트랜잭션

운영자는 고객의 배송 상태를 배송 시작으로 변경하고, 고객은 배송지를 변경하는 것이 동시에 발생하는 상황이다. 이때 요구 사항이 `배송이 시작되면 배송지 변경 불가`라면, 애그리거트의 일관성이 깨질 수가 있다.
이러한 문제를 해결하기 위해서는 트랜잭션 처리가 적용되어야 한다. 대표적인 처리 방식으로는 비관적 락(선점 잠금)과 낙관적 락(비선점 잠금)이 있다.
2. 비관적 락

스레드 2는 스레드 1이 잠금을 해제한 뒤에 애그리거트에 접근할 수 있다. 이처럼 한 스레드의 애그리거트 사용이 끝날 때까지 다른 스레드의 접근을 막는 방식을, 비관적 락이라고 한다.
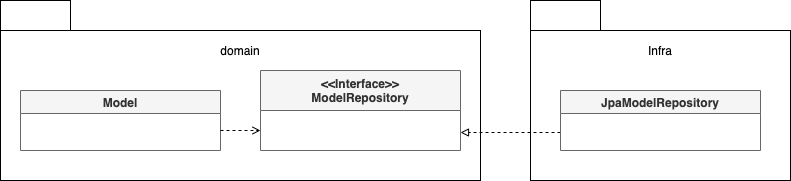
보통 DBMS의 for update와 같은 쿼리를 사용해서 행단위 잠금을 건다. JPA를 사용하면 보다 쉽게 구현할 수 있다.
애그리거트를 동시에 수정할 수 없도록 막기 때문에(상호 배제) 갱신 손실 문제가 발생하지 않는다. 다만 순환 대기, 비선점, 점유 대기를 만족하는 경우에는 데드락이 발생할 수 있는 점을 주의해야 한다.
이에 대한 해결 방법에는 최대 자원 대기 시간을 설정하는 방법이 있다. 이는 힌트를 사용하여 쉽게 구현할 수 있다. 그런데 DBMS에 따라 1) 쿼리별로 대기 시간을 지정하거나 2) 커넥션 단위로만 지정하는 경우로 나뉘니, 사전에 꼭 확인하자
3. 낙관적 락

그림 8.2에서는 운영자와 고객이 변경을 동시에 수행하는 상황이었다. 하지만 그림 8.3에서는 운영자가 사전에 조회한 정보를 바탕으로 변경이 따로 발생하는 상황이다. 이는 비관적 락으로 해결할 수 없지만, 낙관적 락으로는 해결할 수 있다.
낙관적 락은 동시에 접근하는 것을 막는 방식이 아니라, 변경한 데이터를 실제 DBMS에 반영하는 시점메 변경 가능 여부를 확인하는 방식이다. 변경 가능 여부는 버전 관리 방식을 통해 구현할 수 있다.

좀 더 원리를 살펴보자면, 사전에 조회한 애그리거트의 버전 값이 새로 조회한 버전 값과 같은 경우에만 데이터를 수정할 수 있다. 그리고 수정에 성공하면 버전 값을 1 증가시키는 방식이다.
강제 버전 증가
애그리거트는 여러 엔티티와 밸류로 구성되어 있다. 이때 루트 엔티티가 아닌 다른 엔티티의 값이 변경되더라도, 애그리거트 관점에서는 버전이 달라져야 하는 게 올바르다. 이 역시 JPA는 관련 기능을 지원한다.
4. 오프라인 비관적 락
사실 비관적 락을 사용해서 그림 8.3을 해결하는 방법이 있다.
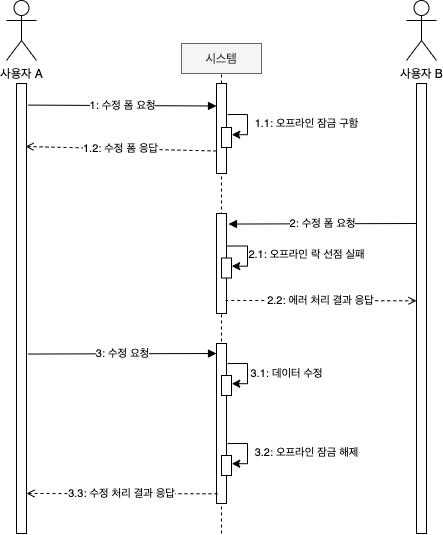
첫 번째 트랜잭션에서 오프라인 락을 걸고 마지막 트랜잭션에서 락을 해제하면 동시성 문제를 해소할 수 있다. 이러한 방식을 오프라인 비관적 락이라고 부른다.
락을 걸 때는 애그리거트에 lockId를 저장하고, 이후에 lockId를 사용하여 락을 해제하는 방식으로 구현할 수 있다. 사용자가 락을 걸기만 하고 해제하지 않을 수도 있으므로, 잠금 유효 시간을 가져야 함을 유의하자.
5. 비관적 락과 낙관적 락
그러면 비관적 락과 낙관적 락을 언제 사용해야 할까? 결론부터 말하자면 낙관적 락은 많은 충돌이 예상되지 않을 때(낙관적인 상황) 사용하고, 비관적 락은 잦은 충돌이 예상될 때(비관적인 상황) 사용하면 된다.
갱신 충돌이 자주 발생하지 않는 경우에는 낙관적 락이 성능이 더 좋다. 비관적 락은 다른 트랜잭션이 접근하지 못하도록 락을 걸기 때문에 동시성이 떨어지기 때문이다. 하지만 반대되는 상황에서는 그렇지 않다.
충돌이 잦을수록 트랜잭션이 중단되어 롤백할 가능성이 높아진다. 하지만 롤백은 보류 중인 모든 변경 사항을 되돌려야 하므로 비용이 많이 드는 작업이다.
이러한 이유로 충돌이 자주 발생하는 경우에는 비관적 락이 더 적합할 수 있다.
참고자료
https://stackoverflow.com/questions/129329/optimistic-vs-pessimistic-locking
'개발 도서 및 강의 > 도메인 주도 개발 시작하기' 카테고리의 다른 글
| 7장 도메인 서비스 (0) | 2023.03.24 |
|---|---|
| 6장 응용 서비스와 표현 영역 (0) | 2023.03.24 |
| 4장 리포지터리와 모델 구현 (0) | 2023.03.17 |
| 3장 애그리거트 (1) | 2023.03.17 |
| 2장 아키텍처 개요 (0) | 2023.03.17 |